背景
网上的关于c语言内存分配的文章满天飞,先随便荡一份事例,但是从不同的角度讲一下这个案例
对于下面的代码生成的程序,基本采用如下命令反编译
objdump -M intel -s -d -x main.o | objdump -s -x -d -M intel a.out | nl -ba
-M intel 输出intel寄存格式,便于阅读
-s 输出section的信息
-d 反汇编.text的逻辑
-x 尽可能反编译信息
全局/静态初始化
首先看看全局初始化过的变量,它应该在反汇编哪个地方呢?
就是代码中变量 a 所对应的 100
#include <stdio.h>
int a = 100;
int main() {
static int b = 101;
printf("%d %d\n", a, b);
return 0;
}
//为什么过滤64,是因为100的16进制是64
objdump -s -x -d -M intel main.o | nl -ba | grep 64
//c源码跟汇编对照
objdump -S main.o

本质上就是存在.data节的
这里面有个问题,我目前还不懂,大概是跟重定向有关系的
就是这些全局/静态初始化变量,作为参数在调用printf的时候
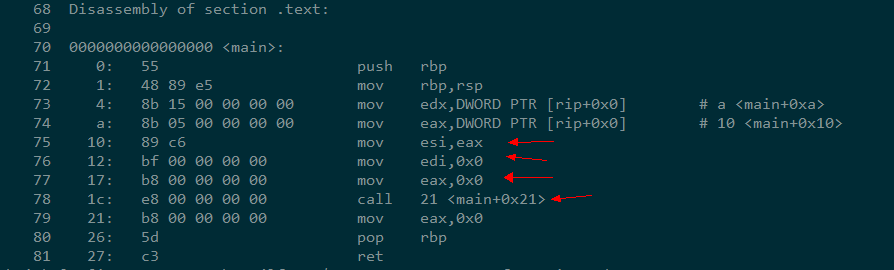
- 没有直接指令操作
esp(rsp)等进行参数压栈 edi的值被赋值为零
而实际在动态调试中
//调试
gdb main
//查看源码,便于下断点
list
//在printf第6行处下断点
b 6
//重启程序,断点断住
r
//调整到汇编角度断点
layout asm
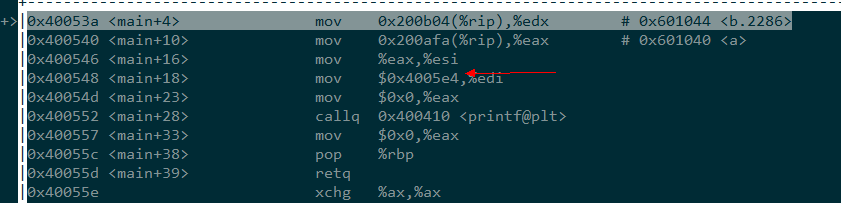
明显立即数不是$0x0
全局/静态未初始化
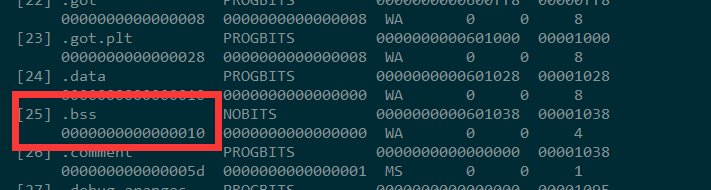
存在.bss,只有段表可以看到,实际生成的文件里面并没有bss节
用readelf -s 或 objdump -t 查看符号表
用readelf -S 或 objdump -h 查看段表
int a;
int main() {
static int b;
return 0;
}
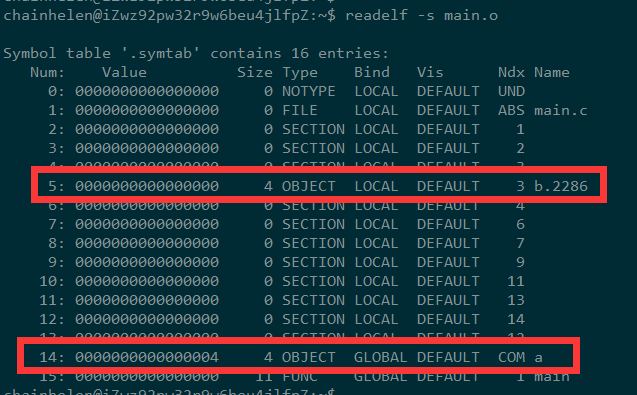
从符号表中可以看到,a、b两个符号都是存在的,大小都是4字节,也就说一共应该是8字节
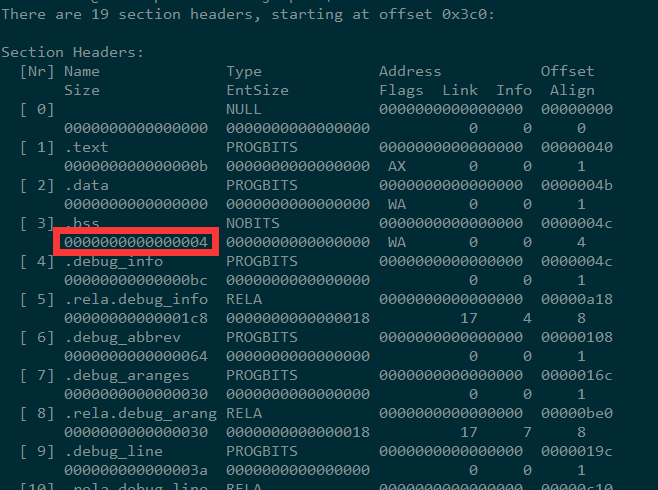
然而实际在.bss段表中,看到.bss的大小只有4字节
翻阅了资料,才意识有些编译器会将全局的未初始化变量存在目标文件.bss段,只是一个"COMMON符号"
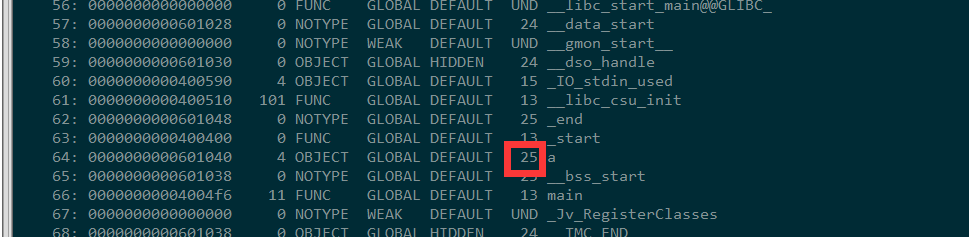
有些却不是,只是预留一个未定义的全局变量符号,等到最终链接成可执行文件的时候,再在.bss分配空间
我们编译成main可执行文件,再来一下,发现变量a已经不是COMMON符号,但是这时候.bss的空间到了10字节,应该是链接时还包括了其他的变量
栈/堆
栈堆是动态生成的,所以只有运行时才有自己的内存空间
但是我们可以通过.text段观察、心中模拟运行时是什么样的内存
int main() {
int b = 10;
int *a = (int *)malloc(1 * (sizeof(int)));
*a = 11;
return 0;
}
看一下.text反汇编是什么样
//objdump -d -x main.o
Disassembly of section .text:
0000000000000000 <main>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 10 sub $0x10,%rsp
8: c7 45 f4 0a 00 00 00 movl $0xa,-0xc(%rbp)
f: bf 04 00 00 00 mov $0x4,%edi
14: e8 00 00 00 00 callq 19 <main+0x19>
15: R_X86_64_PC32 malloc-0x4
19: 48 89 45 f8 mov %rax,-0x8(%rbp)
1d: 48 8b 45 f8 mov -0x8(%rbp),%rax
21: c7 00 0b 00 00 00 movl $0xb,(%rax)
27: b8 00 00 00 00 mov $0x0,%eax
2c: c9 leaveq
2d: c3 retq
上面可以看到
[0, 4)字节汇编是在保存栈帧
[4,8)字节汇编是在开辟一个0x10,即16字节的栈空间
[8, f)字节汇编对应源码中的b = 10,因为10的16进制是0xa
[21, 27) %rax存放的是源码中a指针,这一句就是源码中的*a = 11,因为11的16进制是0xb
也就是说实际上,a、b变量都在栈上面,只是a的指针指向的内存是在堆上
字符串常量区
#include <stdio.h>
int main() {
char *a = "123";
char *b = "123";
if(a == b) {
printf("==\n");
} else {
printf("!=\n");
}
return 0;
}
gcc -g -c main.c -o main
objdump -s main.o
// .rodata段如下
Contents of section .rodata:
0000 31323300 3d3d0021 3d00 123.==.!=.
通过上面分析,我们知道,a、b的内存在栈上,而a,b指向的内存空间是在字符串常量区,也就是.rodata区(read only data)
对于编译器来说,常量有些地方可以优化的(常量折叠),比如这里面的"123"是相同的常量,编译器只存了一份
所以导致a、b变量都指向相同的"123"地址,上述代码指向输出"=="