分布式Id
snowflake 是一种分布式id唯一算法,相比较uuid算法生成方式,snowflake生成的是一个int64大整型,并且是大致递增
我发现网上对于该算法的描述,在位数偏移上是由差异的,但是整体思路是一致的
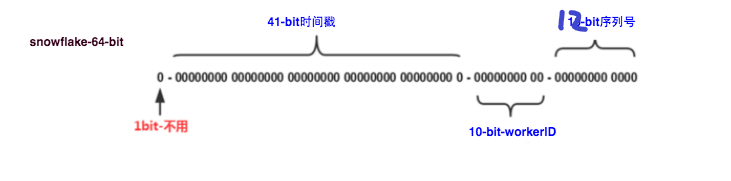
这里的10-bit workerId在有的源码里面是分成两个 workerId 、data的5-bit大小
可以大致算一下,1毫秒1单点能生成2 ^ 12 = 4096个id,总共能部署 2 ^ 10 = 1024 个节点,也就是1毫秒最大能生成400多万个id
我按照算法思路写了如下代码
package main
import (
"errors"
"fmt"
"sync"
"time"
)
var (
// 1288834974657 是 (Thu, 04 Nov 2010 01:42:54 GMT) 这一时刻到1970-01-01 00:00:00时刻所经过的毫秒数。当前时刻减去1288834974657 的值刚好在2^41 里,因此占41位。 所以这个数是为了让时间戳占41位才特地算出来的。
epoch int64 = 1288834974657
// 掩码4095 (0x111111111111=0xfff=4095)
// 其实我认为改成(1 << StepBits) - 1也是可以的
stepMask int64 = -1 ^ (-1 << 12)
)
type Node struct {
mu sync.Mutex
lastTimeStamp int64
workId int64
step int64
}
func NewNode(workId int64) (*Node, error) {
if workId < 0 || workId >= (1<<10) {
return nil, errors.New(fmt.Sprintf("Invild workId : %d.\n", workId))
}
return &Node{
lastTimeStamp: 0,
workId: workId,
step: 0,
}, nil
}
func (n *Node) Generator() (int64, error) {
n.mu.Lock()
defer n.mu.Unlock()
now := time.Now().UnixNano() / 1000000
if now < n.lastTimeStamp {
return 0, errors.New(fmt.Sprintf("Clock is moving backwards.Rejecting requests until %d.\n", n.lastTimeStamp))
}
if now == n.lastTimeStamp {
n.step = (n.step + 1) & stepMask
if n.step == 0 {
for now <= n.lastTimeStamp {
now = time.Now().UnixNano() / 1000000
}
}
} else {
n.step = 0
}
n.lastTimeStamp = now
return ((n.lastTimeStamp - epoch) << (10 + 12)) |
(n.workId << (12)) |
(n.step), nil
}
func main() {
// 1
func() {
_, err := NewNode(1024)
fmt.Printf("1. Get one error: %s\n", err.Error())
}()
// 2
for i := 0; i < 1024; i++ {
node, _ := NewNode(int64(i))
id1, _ := node.Generator()
id2, _ := node.Generator()
fmt.Printf("2. WorkId %4d generator %d %d\n", i, id1, id2)
}
}
为什么是大致递增
主要时间戳放在前面一点,所以时间影响比较大,同一毫秒内的id就很难区分先后
etcdv3
使用etcdv3来实现抢占workid,可以在下文中etcd/mutex.go中看到原生代码中的分布式锁
注意以下的事务
client := m.s.Client()
m.myKey = fmt.Sprintf("%s%x", m.pfx, s.Lease())
cmp := v3.Compare(v3.CreateRevision(m.myKey), "=", 0)
// put self in lock waiters via myKey; oldest waiter holds lock
put := v3.OpPut(m.myKey, "", v3.WithLease(s.Lease()))
// reuse key in case this session already holds the lock
get := v3.OpGet(m.myKey)
// fetch current holder to complete uncontended path with only one RPC
getOwner := v3.OpGet(m.pfx, v3.WithFirstCreate()...)
resp, err := client.Txn(ctx).If(cmp).Then(put, getOwner).Else(get, getOwner).Commit()
if err != nil {
return err
}
在分布式锁中,注意使用租赁的概念,使用续租方式不断延期
// 续约
if keepAliveRes, err = lease.KeepAlive(context.TODO(), leaseGrantResponse.ID); err != nil {
log.Fatal(err)
}
这里有两点细节,keepAliveRes是一个chan,可以不断拿到每次续约过后的报文
1. 续约的周期默认是`契约时间的` 1/3 (代码里)
2. 本身有重试机制,500ms一次,时间连续超过 一次周期 `chan`,还是有错误,那么将会读取出 nil,并且在标准错误里面会有错误输出
// 重试 retryConnWait is how long to wait before retrying request due to an error
retryConnWait = 500 * time.Millisecond
// 续约 send update to all channels
nextKeepAlive := time.Now().Add((time.Duration(karesp.TTL) * time.Second) / 3.0)
所以使用者并不需要担心网络波动等原因(3次),添加大量高可用代码(重试/读超时)
参考
baidu/uid-generator
理解分布式id生成算法SnowFlake
Leaf——美团点评分布式ID生成系统
Twitter的分布式自增ID算法snowflake (Java版)
分布式唯一id:snowflake算法思考
etcd v3客户端用法
用Etcd实现分布式锁和选主
基于go+etcd实现分布式锁
etcd/clientv3/concurrency/mutex.go