起因
公司同事发现,其topic数据均摊在k8s里面 5个 nsqd
但是其中两个nsqd对应的消费channel已经出现积压,甚至落盘过万条数据
触发条件
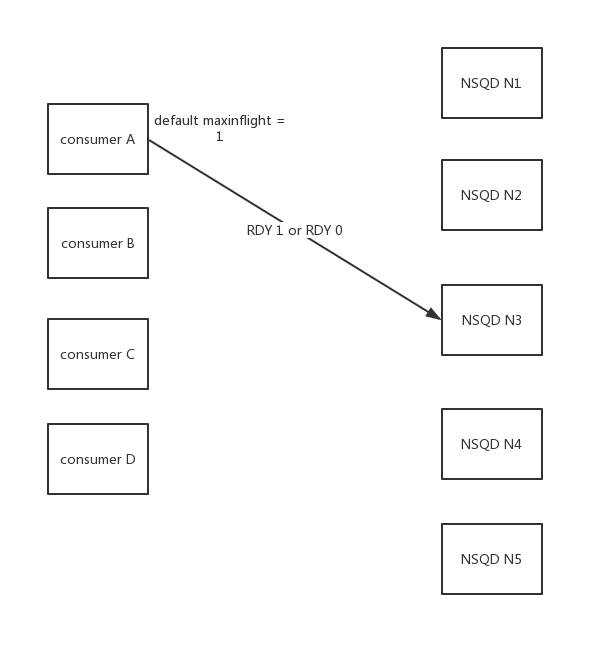
注意每个 consumer 与 每个 NSQD 都有连接(图中没有画出)
每个consumer的maxinflight设置都是1
使用最新的官方sdk版本go-nsq v1.0.7
参数解释
这里面有两个参数需要解释一下,但是是从
consumer的角度解释的,同样的参数在nsqd中可能含义不一样
RDY是代表当前消费者还可以接受多少条消息,进行处理(在上面场景,大部分情况都是0、1)
maxinflight代表是当前还未完全处理完的消息最大条数(默认是1条)
负载均衡
例如从consumer A角度来看,有这样的场景,len(A.conns) > maxinflight
也就是说,consumer A在同一时间内,不能够RDY多个nsqd,所以只能暂时选取其中一个,然后过一段时间再来处理其他的nsqd上面的消息,实际在consumer里面确实有一个定时器去做这件事
func (r *Consumer) rdyLoop() {
redistributeTicker := time.NewTicker(r.config.RDYRedistributeInterval)
for {
select {
case <-redistributeTicker.C:
r.redistributeRDY()
...
}
}
...
}
这里面注意,只有len(conns) > int(maxInFlight)才会出现重新分配RDY
以下代码已经添加注释,整个流程
func (r *Consumer) redistributeRDY() {
...
// 当前消费者无法承担所有连接的消息
if len(conns) > int(maxInFlight) {
r.log(LogLevelDebug, "redistributing RDY state (%d conns > %d max_in_flight)",
len(conns), maxInFlight)
atomic.StoreInt32(&r.needRDYRedistributed, 1)
}
...
if !atomic.CompareAndSwapInt32(&r.needRDYRedistributed, 1, 0) {
return
}
for _, c := range conns {
...
// 如果已经给当前nsqd(conn)的分配过rdy,需要考虑是否收回,满足两个条件就可以收回
// 1. 距离上一次发送非零RDY并且一直未收到消息,时间已经超过 LowRdyIdleTimeout(默认10s)
// 2. 距离上一次该rdy发给conn,时间已经超过 LowRdyTimeout(默认30s)
if rdyCount > 0 {
if lastMsgDuration > r.config.LowRdyIdleTimeout {
r.updateRDY(c, 0)
} else if lastRdyDuration > r.config.LowRdyTimeout {
r.updateRDY(c, 0)
}
}
possibleConns = append(possibleConns, c)
}
availableMaxInFlight := int64(maxInFlight) - atomic.LoadInt64(&r.totalRdyCount)
if r.inBackoff() {
availableMaxInFlight = 1 - atomic.LoadInt64(&r.totalRdyCount)
}
// 重新分配的算法,里面有个随机方式
for len(possibleConns) > 0 && availableMaxInFlight > 0 {
availableMaxInFlight--
r.rngMtx.Lock()
i := r.rng.Int() % len(possibleConns)
r.rngMtx.Unlock()
c := possibleConns[i]
// delete
possibleConns = append(possibleConns[:i], possibleConns[i+1:]...)
r.log(LogLevelDebug, "(%s) redistributing RDY", c.String())
r.updateRDY(c, 1)
}
}
根据以上的代码,如果生产者一直生产消息,发送了非零RDY,那么消费者一定不会出现收不到消息的(无网络问题),所以发生重新分配RDY只能是上面的第二种条件,"距离上一次该rdy发给conn,时间已经超过 LowRdyTimeout(默认30s)"。
可以得出一个结论,我们这种场景下,每30s应该会发生一次重新分配RDY
矛盾
下图是consumer与其中一个nsqd的消费消息报文
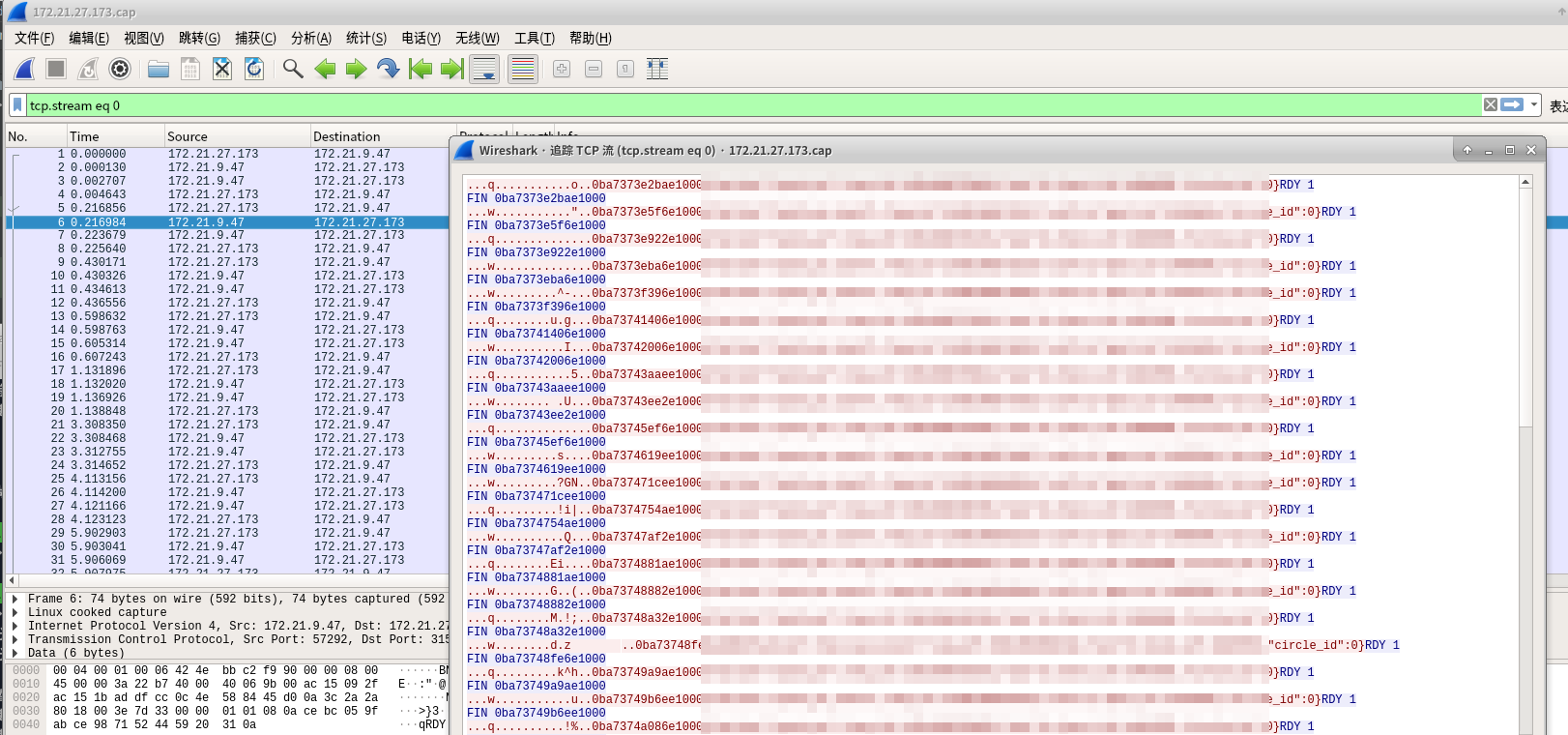
第一个RDY(图中的No.2报文)和第二次RDY(图中的No.6报文)之前只差了200ms,跟30s差太大了
如果以此频率发送RDY(上述发生重新分配RDY条件2无法满足),将会导致该consumer从其他nsqd消费消息(无法负载均衡)
原因
提交记录
根本问题是,消费完一条消息,消费者无需立即再次发送RDY的状态(nsqd是有保存的)
在使用gomod拉取go-nsq代码是最新的tagv1.0.7, 然而这个tag两年都没有更新过版本,实际master分支已经合并上面的提交修复了