起因
之前遇到一些场景,使用了分布式锁,目前来做一个总结
redis
1. 单点redis
单点redis场景,主要容易存在单点故障。(分布式高可用的手段:1.单点故障转移 2.数据冗余)
// 获取锁
SET key value NX PX xmilliseconds
// 删除锁
if redis.call("get", KEYS[1]) == ARGS[1] then
return redis.call("del", KEYS[1])
else
return 0
end
设置key值,需要设置一下随机value,避免锁被其他竞争者删除
设置过期时间,避免客户端崩溃之后,该key永远无法被删除
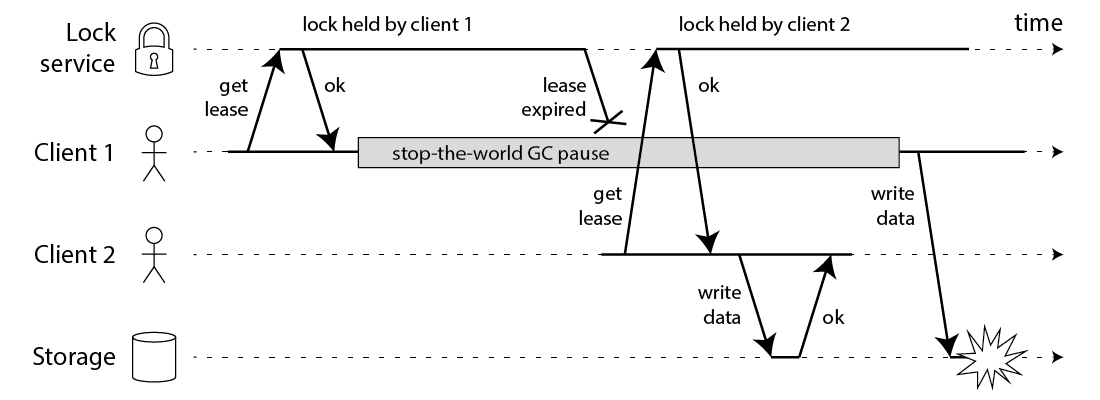
删除需要使用lua脚本,因为redis单线程执行lua能保证原子性
2019年qconf大会 苏宁拼团讲到两点,非常现实
1. 过期时间不好把控;不能太短,否则业务还没完(或者GC之类),锁就没了;如果过长,client一旦崩溃,就导致锁长时间停留
2. failover 单点问题
2. Redlock
原理上跟单机redis差不多,只是需要对所有节点都要发起请求
1. 获取当前时间戳 t1
2. 依次向所有的redis,发起加锁过程(每次请求最好设置超时,远小于锁的过期时间),只要超过一半节点成功设置,就认为获取的到锁;反之获取锁失败;记下当前的时间戳 t2
3. 如果获取成功,那么当前锁的有效时间值 = 设置过期时间 - (t2 - t1)
4. 如果获取失败,需要向所有节点发送删除锁
考虑一下 redis 某个节点崩溃场景
A、B、C、D、E 5个节点
1. client甲 在节点A、B、C上面上锁成功
2. C崩溃
3. C重新启动,丧失了锁信息
4. client乙 在节点C、D、E上面上锁成功
另外也没有解决超时时间长短问题
3. fencing-tokens
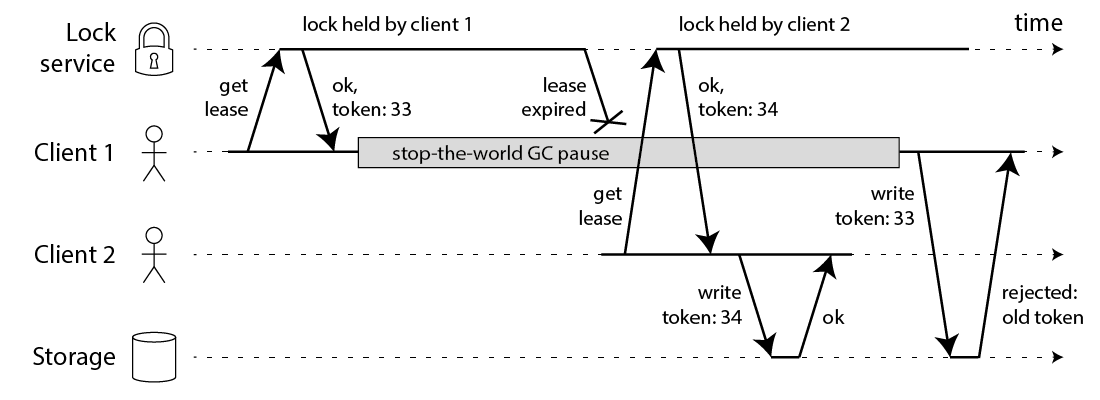
- 其实对于这种方式需要
storage支持乐观锁 - 并且从逻辑上来看
Lock service并没有存在的必要,只需要一个能够生成递增token服务即可
实际生产中是可以缓解 Storage 的竞争关系
4. zookeeper
zookeeper(etcd、consul等类似)等主要能解决一旦出现客户端崩溃,Lock service能够感知
就是锁本身是不需要做过期的,本质上是把锁上面的过期时间,扔给了长链session心跳包(etcd里面是lease)
而且分布式协调器通常是带有watch能力的,也就是说其他client在竞争不到锁的时候,线程(协程)可以直接直观阻塞
(本质上来还是很难解决,当出现客户端gc、或者网络延迟,lock被删,导致client1正在操作storage这个时间点还是没有被锁)
看一个分布式锁的etcd例子
package main
import (
"context"
"fmt"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
"log"
"os"
"os/signal"
"time"
)
func main() {
c := make(chan os.Signal)
signal.Notify(c)
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"localhost:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
log.Fatal(err)
}
defer cli.Close()
lockKey := "/lock"
go func () {
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
m := concurrency.NewMutex(session, lockKey)
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go1 get mutex failed " + err.Error())
}
fmt.Printf("go1 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(10) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go1 release lock\n")
}()
go func() {
time.Sleep(time.Duration(2) * time.Second)
session, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
m := concurrency.NewMutex(session, lockKey)
if err := m.Lock(context.TODO()); err != nil {
log.Fatal("go2 get mutex failed " + err.Error())
}
fmt.Printf("go2 get mutex sucess\n")
fmt.Println(m)
time.Sleep(time.Duration(2) * time.Second)
m.Unlock(context.TODO())
fmt.Printf("go2 release lock\n")
}()
<-c
}
这里面需要注意一个惊群效应,每一个client在锁住/lock这个path的时候,实际都已经插入了自己的数据,类似/lock/LEASE_ID,并且返回了各自的index(就是raft算法里面的日志索引),而只有最小的才算是拿到了锁,其他的client需要watch等待。例如client1拿到了锁,client2和client3在等待,而client2拿到的index比client3的更小,那么对于client1删除锁之后,client3其实并不关心,并不需要去watch。所以综上,等待的节点只需要watch比自己index小并且差距最小的节点删除事件即可。